
中國企業報集團主管主辦
中國企業信息交流平臺


 中企網微博
中企網微博 中企網微信
中企網微信
中國企業報集團主管主辦
中國企業信息交流平臺
中企網微博中企網微信
【1.0時代? ?終端+Excel】
1.0時代,我們獲取數據的方式是在終端點開瀏覽器,把數據通過 Excel 下載到本地中使用。Excel 中各種透視表與插件組合滿足了絕大多數小批量數據使用的場景。Excel+終端瀏覽器,基本解決了小批量數據使用的問題。
【2.0時代? ?SQL+單一數據來源】
隨著研究的深入、數據維度的拓展、數據規范的清晰,結構化數據開始成為標配。相比于過去的數據瀏覽器提取方式,SQL 通過一個或幾個語句就能實現全部數據的提取,讓用戶倍感輕松。信息化帶來的效率提升,仿佛經歷了“工業革命”般的體驗。
【2.0時代后期? ?更高的算力需求】
逐漸地,SQL 也開始暴露一些無法滿足研究需求的問題。假如研究的重心放在組合管理、因子挖掘、風險控制領域,SQL 似乎既不能滿足計算要求、也無法滿足數據處理的時效性要求,這意味著,用戶需要花費大量的精力提高一點點效率。
于是,DolphinDB 與聚源也開始給
近日,書香門地集團檢測中心參加2023年林產品檢驗檢測能力驗證活動中人造板甲醛釋放量、吸水厚度膨脹率和密度3個檢測項目,均取得滿意結果,這已是書香門地集團檢測中心連續4年取得該榮譽。
該活動由國家林業和草原局林產品質量和標準化研究中心組織、國家人造板與木竹制品質量檢驗中心等承辦,是一份給承擔林產品質量監測任務的各級檢驗檢測機構和自愿參與的實驗室的年度盲樣考卷,是評價檢驗檢測實驗室檢測能力的有效手段。

書香門地集團檢測中心連續4年取得國家林業和草原局林產品質量和標準化研究中心結果滿意的考核,充分說明書香門地集團檢測能力持續保證結果的準確性。年考并不是終點,而是一個新的開始。在中國林科院木工所的培訓和指導下,書香門地集團充分利用通知結果改進檢測中心檢測水平,確保檢驗檢測能力持續滿足要求并不斷提升。
未來,書香門地集團檢測中心將不斷提高質量控制與運行管理水平,持續加強檢驗檢測能力建設,擴展更多檢測項目,為原物料和產品在采購、研發和生產等各個環節提供數據支撐,為書香門地高質量發展保駕護航,為消費者甄選優質健康家居產品。
合作探索一種全新的業務模式。
【3.0時代? ?探索高質量+高性能】
高質量數據與高性能數據庫的融合是市場對3.0時代新業務場景的期待,但目前來看仍存在一些難題待解。以MySQL為例,在海量的時序數據場景下存在一些問題:
·存儲成本大:對于時序數據壓縮不佳,需占用大量機器資源。
·維護成本高:單機系統,需要在上層人工的分庫分表,維護成本高。
·寫入吞吐低:單機寫入吞吐低,很難滿足時序數據千萬級的寫入壓力(針對tick級數據場景)。
·查詢性能差:海量數據的聚合分析性能差。
在3.0時代的探索過程中,DolphinDB 與聚源數據達成合作,我們為構建一站式行情數據庫服務模式共同努力。
全新的業務場景下,用戶可以通過 DolphinDB 訪問和調用聚源數據庫的各類數據,快速實現高頻數據對接、存儲、查詢、指標計算、因子研究等,助力實現更便捷、更高效的投研。海量數據意味著數據質量高、歷史可追溯時間長、維度多,因此全量數據供應商顯得尤為重要,而數據質量是一切的基礎。
從數據質量的角度:
聚源數據庫以金融證券為核心,服務內容涵蓋投研數據、財富數據、固收數據、風險數據、ESG 數據等,廣泛應用于金融資訊展示、金融投研、大數據分析、風控、量化回測、金融監管等多個領域,經過二十余年的發展,公司與國內券商、基金、保險、信托、銀行、期貨、資產管理公司等機構建立了廣泛的業務合作,確立了在中國金融數據服務領域的領先地位,是中國最優秀的金融資訊服務供應商之一。
從數據庫性能的角度:
SQL 或者單一 Python 的處理方法,無論便攜性還是成本都不算友好。比如計算一個投資組合的協方差矩陣,無法在 SQL 中完成,需要借助額外的 Python 反推回數據庫。高性能時序數據庫 DolphinDB 有出色的內置函數、多范式的腳本語言、靈活的自定義計算,無論是在數據存儲端,還是在復雜分析端,都是比 SQL 和 Python 更優的選擇。以下圖為例:
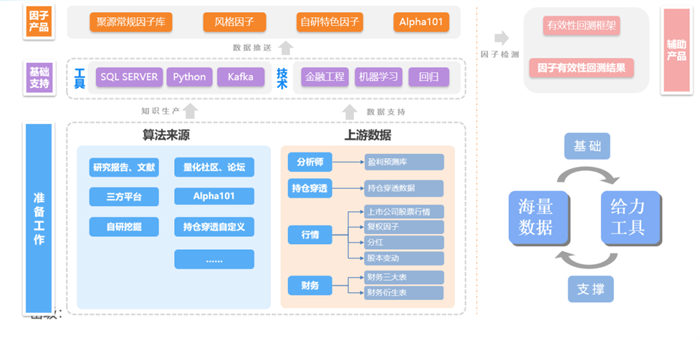
高質量數據、高性能數據庫二者怎么融合?從最傳統的量化場景出發,以聚源提供的因子庫為例。
DolphinDB 支持直接加工底層數據結果并且及時反饋結果到使用者手中,量化場景下的基礎因子、特色因子、回測框架都可以直接依托其后的數據基準進行融合。這些步驟的融合幫助用戶解決數據儲存量極大、讀取緩慢的通病。也就意味著,當擁有了捆綁好的高質量基礎數據與高性能平臺的時候,用戶便有了所有想要的內容。同時,因為 DolphinDB 自定義的優勢加上聚源數據除常規的披露數據外,還有包括但不限于其它主流另類數據(司法,工商,輿情,預期、宏觀行業等)等,極大方便機構客戶做特色因子挖掘和回測的工作流程,將原本離散化的工作任務集成式布置在 DolphinDB 上,真正發揮出1+1融合但是產出遠大于2的效果。
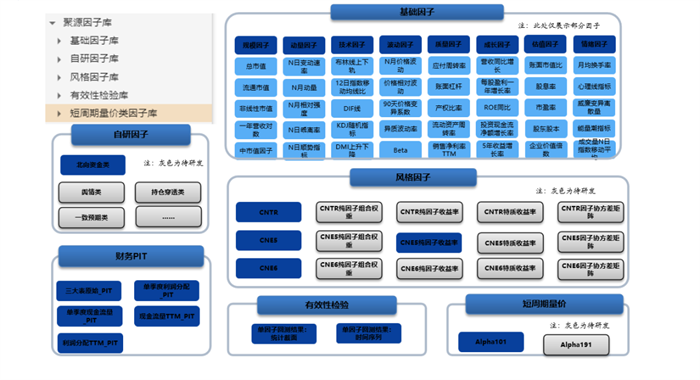
數據質量與數據庫性能的優勢相互結合,機構可以直接享受到聚源高質量數據加 DolphinDB 高性能數據庫的一站式服務。
除此之外,分布式高性能的數據存儲,必然對高頻率的數據量處理有著顯著優勢,對于聚源在金融全場景下涵蓋的各更新頻率不一的數據,科學合理的插值方法,是提高數據頻率的有效手段;因子算法部署在更為高頻的數據空間(如 Alpha191 算法由日K,調整為 1分鐘K),也是挖掘非線性因子的,進入市場顆粒化程度更深領域的主要路徑。數據升頻與 DolphinDB 的高性能協作,勢必會開辟量化數據場景的新賽道。
這也意味著,3.0時代將迎來數據庫與編程語言的融合。
在傳統的數據庫時代,我們更看重數據的寫入,所以我們強調數據庫的一致性、原子性、持久性等,而用于分析的 SQL 語句功能則相對簡單,復雜的分析和計算通常由更高級的編程語言(如 C++, Python 等)來完成。在海量數據時代,我們更看重數據的讀取,也就是通過對海量數據的分析,發掘數據背后的價值,數據分析的時效性則對企業的競爭能力至關重要。未來 SQL 語句和更高級的編程語言也將走向融合,高質量的數據+高性能的數據庫將解決數據來源廣、時效性差、成本開銷大等一系列長期困擾市場的難題。
基于此,DolphinDB 與聚源,在路上。
相關稿件
