
中國企業報集團主管主辦
中國企業信息交流平臺


 中企網微博
中企網微博 中企網微信
中企網微信
中國企業報集團主管主辦
中國企業信息交流平臺
中企網微博中企網微信
11月27日,浪潮電子信息產業股份有限公司在京發布“源2.0”基礎大模型,并宣布全面開源。“源2.0”包括102B(1026億)、51B(518億)、2B(21億)三種參數規模的模型,在編程、推理、邏輯等方面展示出了先進的能力。
基礎大模型的關鍵能力是大模型行業和應用落地能力表現的核心支撐。在算法、數據和算力等方面,“源2.0”提出了新的改進方法并獲得了能力的提升。
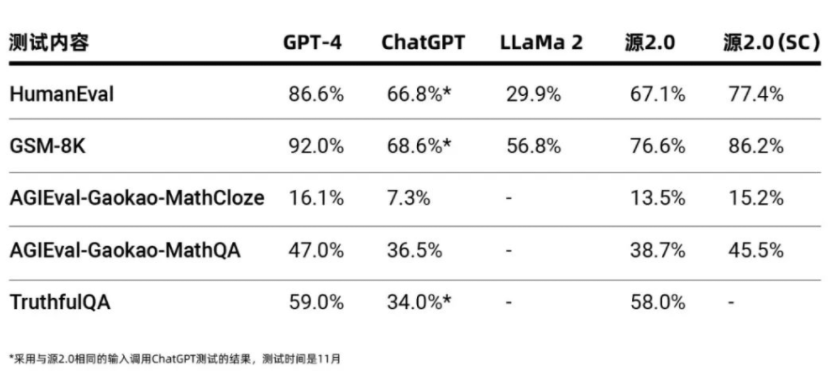
“源2.0”能力測評數據(浪潮信息供圖)
如在算法方面,“源2.0”提出并采用了一種新型的注意力算法結構“局部注意力過濾增強機制”,讓大模型在使用更少的訓練算力、更小的模型參數的情況下,同樣可以獲得更高的模型精度和涌現能力;數據方面,降低了互聯網語料內容占比,通過使用中英文書籍、百科、論文等資料,結合高效的數據清洗流程,為大模型訓練提供了高質量的學科專業數據集和邏輯推理數據集。
作為千億級基礎大模型,“源2.0”在業界公開的評測上進行了代碼生成、數學問題求解、事實問答方面的能力測試,測試結果顯示,“源2.0”在多項模型評測中展示出了較為先進的能力表現。
“源2.0”采用全面開源策略,全系列模型參數和代碼均可免費下載使用。“大模型的開源開放可以使不同模型之間共享底層數據、算法和代碼,有利于打破大模型孤島,促進模型之間協作和更新迭代;同時,有利于以更豐富的高質量行業數據反哺模型,打造更強的技術產品,加速商業化進程。目前,業內仍沒有完全開源可商用的千億大模型,我們希望‘源2.0’能夠為國內外開發者、研究機構、科技企業提供堅實的底座和成長的土壤。”浪潮信息高級副總裁劉軍說。
浪潮信息長期致力于人工智能算力基礎設施產品的研發,2021年在業界率先推出了中文AI巨量模型“源1.0”,參數規模達2457億,落地南京智算中心。此次發布的“源2.0”較前一版本實現了能力的全面提升。(記者溫競華)
相關稿件
