
中國企業報集團主管主辦
中國企業信息交流平臺


 中企網微博
中企網微博 中企網微信
中企網微信
中國企業報集團主管主辦
中國企業信息交流平臺
中企網微博中企網微信

近日,天池FT-Data Ranker競賽落下帷幕,天翼云智能邊緣事業部AI團隊(后稱天翼云AI團隊)憑借在大語言模型(LLM)訓練數據增強方面的卓越研究,榮獲大語言模型微調數據競賽——7B模型賽道冠軍。
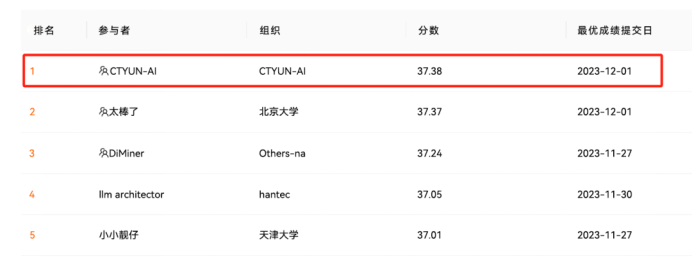
FT-Data Ranker競賽是一場面向大語言模型研究、以數據為中心的競賽,吸引了包括來自北京大學、Hantec等知名高校、研究機構、企業的近400支優秀隊伍參賽。天翼云在激烈的角逐中脫穎而出,展現出強大的技術創新能力。
數據在大語言模型(LLM)的能力打造中發揮著至關重要的作用,更好地構建和處理數據集成為大語言模型領域研究的重點。本次競賽的核心在于獨立、精確地評估和提升數據集質量,加速形成基準驅動的數據開發流程,增強大語言模型數據處理能力,提高該領域對數據質量和數據優化的理解能力。本次競賽特別關注微調(Fine-tuning)階段的數據,要求參賽者對原始數據集進行清洗、過濾和增強,利用新數據集對特定模型進行微調,并在測試集上進行性能排名。相關稿件
