
中國企業報集團主管主辦
中國企業信息交流平臺


 中企網微博
中企網微博 中企網微信
中企網微信
中國企業報集團主管主辦
中國企業信息交流平臺
中企網微博中企網微信
據斯坦福大學報告顯示,自2003年以來,GPU性能提高了約7000倍,單位性能價格也提高了5600倍。GPU已經是推動 AI 技術進步的關鍵動力。

H100 GPU(圖片來源:NVIDIA官網)
數周之前,芝加哥大學商學院的魯海昊教授發現,原本傳統依賴英特爾/AMD CPU(中央處理器)芯片進行計算的數學規劃求解器(Solver,下稱“求解器”),如今卻可以突破技術瓶頸。
具體來說,魯海昊教授團隊通過實驗發現,求解器能夠通過英偉達GPU(圖形處理器)和CUDA庫函數,設計高效的數學規劃算法cuPDLP來求解超大規模問題,并體現出了計算優越性,其研發的cuPDLP軟件(Julia版本)也驗證了這一點。而該研究成果日前發表在arxiv上。
此后,魯海昊團隊與斯坦福大學博士、杉數科技首席科學家葛冬冬教授團隊進行了緊密合作:在最頂級的計算設施,英偉達GPU H100多顯卡集群上,團隊對自己研發的cuPDLP-C求解軟件(C語言版本)進行了實驗,驗證GPU能否實現線性規劃問題求解的“彎道超車”。
鈦媒體App獲悉,2023年12月8日,杉數科技團隊在中國運籌學會算法軟件與應用分會成立大會上,報告了他們在英偉達H100 GPU顯卡上,成功驗證了cuPDLP-C求解超大規模線性規劃問題(LP problem)的顯著優勢。在多個經典測試集上,對于大規模問題,算法體現出了不亞于傳統商業求解器的表現,并且在多個大問題上有明顯求解優勢。
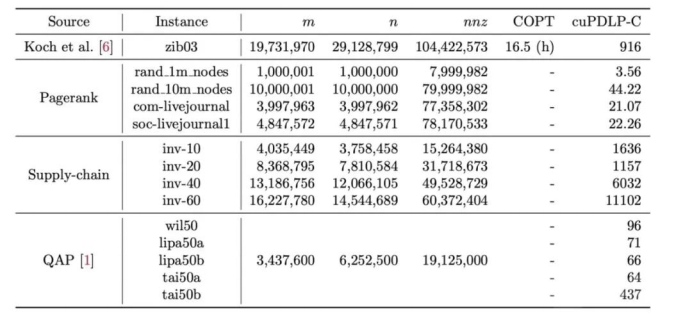
例如,從求解效率來看,領域內著名的測試問題zib03,相比四年前用CPU求解的16.5個小時(用英特爾至強E7-8880 v4),如今在英偉達H100下,cuPDLP-C求解計算時間直接縮短至916秒,時間縮短了64倍。
相較于2009年的CPLEX,計算時間從139天到現在的15分鐘,這完全顛覆了數學規劃算法設計“只有CPU能做”的傳統認知,“降維打擊式”地提升了求解計算效率。同時,由于目前cuPDLP-C已經在GitHub上開源,因此整個成果也將讓更多人受益。
葛冬冬對鈦媒體App表示,“這件事意義重大,它將在未來3-5年對整個運籌學從科研到產業都會產生巨大改變。某種程度上,我認為它將開啟一個運籌學科新的‘大航海時代’。”
“有四點對領域的可能沖擊吧。首先,這套算法思想推廣之后,不僅用在線性系統上,而且對整個連續優化領域都會產生影響,進而深刻影響整數規劃計算領域,這對應求解器應用場景中80%的問題;第二,GPU相關的一階算法設計和執行相對簡單,這將使得求解器社區部分模型對應的算法開源化;而專業求解器以后可能跟目前許多toB的AI公司相似,在專業求解和基于GPU的函數定制服務方面都可以發力,帶來新的商業機會。第三,求解器會變得更加重視硬件,將需要大量適配的專用高精度計算顯卡,以及需要高效的庫函數實現。國內很多 AI 芯片也可以應用,形成一個軟硬一體化的生態;求解器以后的服務也更可能呈現一個軟硬一體化綁定的服務能力。第四,有鑒于求解能力限制,整個運籌學研究的核心之一其實就是如何將大問題分解,分步驟,或者降維求解,而隨著GPU求解算法的“暴力”求解大問題能力劇增,可以預期運籌學領域,也包括相關的多個商科和工科領域的科研范式和產業形態也將隨之極大改變,甚至重塑。”葛冬冬告訴鈦媒體App。
很顯然,通過GPU顯卡的算力加持,對已經發展70余年、古老且嚴謹的運籌學科將會帶來革命性的沖擊。
計算時間縮短超過64倍,GPU芯片將加速求解更多復雜問題
運籌學是近代應用數學的一個分支,主要是研究如何將生產、管理等事件中出現的優化問題加以提煉,然后利用數學方法進行解決的學科。
美國物理學家,曾任加州大學柏克萊分校教授的Charles Kittel早在1947年首次提到“Operations Research”一詞,中國則在1957年由中國工程院院士許國志、清華大學基礎科部教授周華章正式定名為“運籌學”,并于1980年成立中國運籌學會(ORSC)。運籌學在全球發展至今已超過70年。
其中,數學規劃是將現實問題轉化為數學模型并求解的過程。數學規劃求解器作為這一過程的核心軟件,專門針對多種線性、整數和非線性規劃模型進行算法優化。它可以被視為一個“黑盒子”系統,業界亦稱之為算法領域的“芯片”。
求解器的重要意義在于,它能解決生活中非常復雜的應用數學問題。例如,2018年平昌冬奧會的閉幕式上,中國接棒八分鐘展示里出現的無人倉機器人引起全球關注。但如何計算這些機器人的運行路線,為了確保這些機器人運行高效且避免碰撞,需要依賴最優算法,而背后依靠的就是求解器。
在此之前,求解器的核心計算硬件大部分依賴于CPU(中央處理器)芯片,主要原因是CPU的通用能力可以更廣泛應用于眾多計算系統和 算法實現,而且英特爾、AMD相關軟件框架都非常齊全,特別是復雜高精度的各種矩陣運算,大大降低求解規劃成本,并提高計算效能。
葛冬冬指出,芯片這類硬件是求解器底層的核心設施。
長期以來,GPU采用與CPU不同的底層架構,計算核心數量、軟件和性能處理方案與CPU的底層邏輯差異極大。而國內外科研人員希望能夠通過GPU或是其他類型芯片可實現線性規劃的加速計算,但多次實驗結果顯示,GPU一直無法高效求解算法中的“矩陣求逆”或者“矩陣分解“問題,無論是計算精度(物理原因)還是并行計算,它都無法做到。
“未能突破的原因是,求解器的核心底層只要是這種連續優化問題,不管是線性還是非線性,傳統算法中都躲不開如何高效求解‘矩陣分解’這一步。這個問題解決不了,GPU幾千個計算單元并行加速的優勢就無法體現。”葛冬冬對鈦媒體App表示,“矩陣分解”主要對應線性方程組求解,是計算最關鍵一步。一旦矩陣規模過大或者結構復雜,這個步驟往往會造成內存溢出或者求解時間極長,成為求解桎梏。

杉數科技首席科學家葛冬冬教授
早在2016年,葛冬冬聯合幾位當年在斯坦福的博士同學,共同成立了杉數科技,研制了第一個國產專業求解器,避免受制于人。如今,作為智能決策技術服務公司,杉數科技以其自研大規模商用求解器COPT為核心引擎,打造了“計算引擎+決策技術中臺+業務場景”的端到端智能決策技術平臺,為消費零售、交通物流、能源電網、制造與供應鏈等多個行業提供數字化供應鏈解決方案,利用運籌優化和機器學習找出更優的決策方案,全面提升產業鏈和供應鏈運營效率和效果。
葛冬冬此前向鈦媒體App透露,利用COPT數學優化求解器這種優化決策,可以使生產排程訂單滿足率提高20%,產能損失率降低30%,排產排程人工干預降低70%,非計劃維修降低15%。同時,杉數科技COPT數學優化求解器一直在全球求解器榜單中名列前茅。
而此前葛冬冬團隊研發的COPT求解器系列,主要是利用CPU芯片進行計算處理的。
“事實上,過去十幾年,這個領域內,包括我們,國內外學術界無數人,都在前赴后繼地努力,試圖回答這個問題:GPU/CUDA架構能否對數學規劃求解器起到彎道超車的作用。此前的答案一直為‘否’。”葛冬冬表示。
然而,2023年11月初,葛冬冬的合作伙伴,魯海昊教授在arXiv上發表了一篇論文,他們公開的cuPDLP代碼,通過GPU硬件成功解決了線性規劃求解計算問題,可用在這段Julia代碼中求解線性規劃。
葛冬冬說:“魯老師突破這一長期瓶頸的技術方案,是他們觀察到以前的CPU/GPU混合架構求解中,CPU/GPU之間的交互往往占用了絕大部分耗時,因此他們在此前他們與谷歌合作建立的PDLP求解器基礎上(此求解器可以很好解決GPU計算精度無法達到10^-8精度要求的限制),將整套算法搬到了GPU/CUDA架構下實現。捅破了最后一層窗戶紙!
此后,魯教授與葛冬冬教授領導的杉數COPT團隊緊密合作,提出開源技術方案cuPDLP-C,即用一階方法在GPU上解決線性規劃問題,也是Julia版本cuPDLP.jl的C語言加強版,算法上也做了進一步的改善和提高。
與此同時,通過在目前最強的顯卡H100上的實驗發現,在運籌學最經典的測試集MIPLIB2017的383個線性松弛測試問題求解中,以10^-4 精度要求,cuPDLP-C已經可以求解到379個問題,而以嚴格收斂的標準10^-8 精度要求,cuPDLP-C也可以求解到369個問題。總體求解時間與目前最好的商業求解器的差距也拉近到了2倍(10^-4精度)和6倍(10^-8)精度之內。在測試集那些大問題中的差距明顯更小,在10^-4精度下甚至體現出了計算優勢。此外,葛冬冬團隊還在多個更大規模問題上進行了廣泛測試,cuPDLP-C的優勢明顯,例如zib03問題加速了64倍,而多個更大規模的測試問題,如在谷歌的Pagerank、某國內大企業供應鏈項目問題、經典的二次分配問題(QAP)等問題的測試上,傳統求解器都無法求解,而cuPDLP-C可以做到可行時間內求解。
很顯然,對于超大數學規劃問題,在性能、計算速度、求解數量等方面,GPU都能比CPU都展現出了更好的前景。
杉數科技資深副總裁,技術負責人皇甫博士對鈦媒體App表示,利用GPU硬件,現在cuPDLP-C可以讓之前難以解決的大規模優化問題變得易于解決,推動了模型建立的精確度和規模。以前因CPU限制而采用的非常精密復雜的一些求解技巧可能不再需要。此外,一旦GPU提速上百倍,cuPDLP-C求解優勢可能拓展到其他連續優化領域,極大加速求解過程,讓原本耗時的問題快速得到解決,從而打開新的應用可能性。
葛冬冬告訴鈦媒體App,“這很恐怖。對于運籌學來說,這一技術意外打破了一個長期以來的定論,即GPU在求解數學規劃問題上沒什么加速效果。這一發現會讓整個學術和工業界感到驚訝,因為之前從未有人預料到這種情況。”
他強調,cuPDLP-C技術推翻了運籌學科長期以來的一些共識和定式,超出人們預期,利用GPU提高了求解器的性能潛力,可能使運籌學實現從CPU到GPU計算帶來的“范式轉變”。
目前,cuPDLP-C技術代碼已經開源,相關論文也已經公開發表在arXiv上。
20年性能提高約7000倍,GPU成本過高是否將制約行業發展?
過去一年,以ChatGPT為代表的生成式 AI 技術風靡全球。而作為以95%的市場占有率壟斷了全球 Al 訓練芯片的英偉達,成為了這輪 AI 混戰的最大贏家,其研發的A100/A800、H100/H800等多款 AI 芯片成為 AI 熱潮中的“爆品”。
正如英偉達自己所說:“GPU 已經成為人工智能的稀有金屬,甚至是黃金,因為它們是當今生成式 AI 時代的基礎。”
從技術角度來說,GPU優于CPU,特別是在并行計算能力、能耗效率和CUDA生態等方面,它的高算力和可擴展性使英偉達GPU成為AI加速芯片市場的首選。
根據斯坦福大學最近發布的一項報告顯示,自2003年以來,GPU性能提高了約7000倍,單位性能價格也提高了5600倍。該報告還指出,GPU是推動 AI 技術進步的關鍵動力。
英偉達首席科學家Bill Dally也曾表示,NVIDIA GPU在過去十年中將 AI 推理性能提高了1000倍。
從運籌學角度來看,將CPU替換為GPU,計算能力、計算效率大幅提升。但問題在于,國內可以買到的H100/H800、A100/A800的價格都已經超過20萬/張,再加上存儲、NVLink互連、運維成本等,相比CPU,基于GPU的求解成本將進一步攀高。
那么,求解計算的基礎設施成本,是否會成為未來求解器乃至運籌學發展的重要制約因素?
葛冬冬對鈦媒體App表示,目前只是基于GPU架構的優化算法的“拓荒期”。目前,他們已經與多家國產 GPU芯片廠商開展了廣泛的測試合作,希望能夠利用國產算力推動中國求解器行業發展。確實有部份國產GPU芯片已經具備了跑通算法的能力,但是也確實,還需要在芯片速度和庫函數完備程度上做進一步建設。
而且,他認為,杉數也已經積極與商業伙伴開始積極探索這一技術的落地與應用前景。目前已經開始在電力系統的出清調度問題這一大規模復雜系統問題上,與南網總調合作,探尋運用GPU架構的優化求解算法來加速求解計算的研究。
談及開源與商業化的話題,葛冬冬認為,把cuPDLP-C開源可以推動行業進一步發展,對于商業化求解器來說肯定會有一定沖擊,但GPU求解大規模問題的新思路也帶來了巨大的機會,目前來看,杉數科技在核心技術、商業化等層面還有非常領先的市場競爭優勢。
“新的大門已經推開。過去20年,大家一直在嘗試推開,但門被‘鎖’死了。現在等于是發現‘鎖’能打碎,門是能推開的。這就意味著運籌學算法又進入了一個新的‘大航海時代’,一個堪比‘西部掘金熱’的時代。我們已經走出(開源)這一步。我們對自己的技術有信心,過去七年,從無到有,再到國際領先,杉數一直都在科研、技術和實踐應用上,是國內求解器市場的領航者。在這個經我們的手打開的新時代,我相信,我們是不會落后的。”葛冬冬表示。
相關稿件
